O herói desconhecido da sua dashcam com IA: como o RideView cuida bem do cartão SD
Saiba como o RideView otimiza o desempenho do cartão SD em dashcams com IA para reduzir a fragmentação, prolongar a vida útil do cartão e garantir uma gravação de vídeo confiável.

Uma dashcam com IA grava continuamente, mas quase nada dessas imagens sai do dispositivo — apenas alguns segundos em torno de um evento sinalizado são enviados para a nuvem. Todo o resto permanece no cartão SD. Isso torna o cartão o armazenamento principal da câmera, e não um buffer temporário a caminho de outro lugar, o que sobrecarrega dois aspectos: a velocidade de gravação do cartão, que limita a quantidade de vídeo, áudio e metadados que a câmera pode gravar de forma confiável, e a rapidez com que ele se desgasta, o que determina quanto tempo o hardware dura em campo. Ambos dependem da qualidade do hardware do cartão e, tão importante quanto, da forma como o software grava nele.
Este artigo analisa dois problemas de armazenamento que determinam a confiabilidade e o custo — fragmentação e amplificação de gravação — e como o caminho de gravação do RideView foi estruturado em torno deles.
Mas não há disco giratório — por que a fragmentação seria um problema?
Em um disco rígido mecânico antigo, a fragmentação era obviamente ruim. Um arquivo espalhado pelo disco forçava a cabeça de leitura a buscar os dados de um lado para o outro para reunir as peças, e essa busca era lenta. É por isso que todos nós executávamos a "desfragmentação" durante a noite.
Um cartão SD não tem disco, não tem cabeça de leitura e não tem tempo de busca. Portanto, a conclusão natural é que a fragmentação é um problema resolvido em memórias flash. Para leituras, isso é amplamente verdade. Para escreve, não é — e o motivo está oculto em duas camadas diferentes.
O que realmente acontece dentro do cartão
Primeira camada — o sistema de arquivos (FAT32). Os cartões de câmeras veiculares geralmente são formatados em FAT32, que rastreia cada arquivo como uma cadeia de clusters de 32 KB na Tabela de Alocação de Arquivos. Quando esses clusters estão próximos uns dos outros, o sistema operacional consegue mover o arquivo em poucas transferências grandes e sequenciais. Quando estão espalhados, não consegue: o SO precisa percorrer uma longa cadeia de clusters e dividir o trabalho em muitas pequenas operações de E/S descontínuas — cada uma com sua própria configuração de comando, processamento de conclusão e consulta de metadados.
Essa sobrecarga não tem nada a ver com a memória flash em si. Mais fragmentos significam simplesmente mais operações individuais para mover os mesmos bytes, e isso custa tempo tanto na leitura quanto na gravação.
Segunda camada — a memória flash (o FTL). A memória flash NAND também possui uma restrição física que o sistema de arquivos não consegue ver:
- Ela é gravada em pequenas páginas.
- Ela só pode ser apagada em blocos de apagamentomuito maiores.
- Ela não pode ser sobrescrita no mesmo local — alterar qualquer coisa em um bloco de apagamento significa ler o bloco, mesclar os novos dados, apagá-lo e gravar tudo de volta.
Um controlador chamado Flash Translation Layer (FTL) oculta isso da câmera. E aqui está o problema: quando as gravações são pequenas e dispersas, elas ocupam muitos blocos de apagamento apenas parcialmente, e o FTL é forçado a realizar constantes operações de leitura-modificação-escrita e coleta de lixo apenas para recuperar espaço livre. Tudo isso ocorre por trás da sua gravação e a torna mais lenta. Em vez disso, forneça ao cartão gravações grandes, sequenciais e contíguas, e o FTL preencherá blocos de apagamento inteiros em uma única passagem limpa — sem necessidade de reorganização.
Portanto, no armazenamento flash, a fragmentação não custa tempo de busca. Ela custa E/S extra na camada FAT32 e força o FTL do cartão a entrar em seu modo mais lento. As leituras evitam esse segundo custo completamente, porque ler nunca aciona um apagamento ou coleta de lixo — que é exatamente o motivo pelo qual a fragmentação prejudica muito mais as gravações do que as leituras.
Não queríamos discutir sobre isso — então medimos.
Teoria é uma coisa; queríamos um número. Realizamos um teste controlado em um cartão FAT32 de 128 GB, preenchendo-o de duas maneiras e comparando-as diretamente:
- Fragmentado: muitos gravadores rodando em paralelo, cada um liberando dados frequentemente, fazendo com que o FAT32 intercalasse clusters entre os arquivos.
- Contíguo: um único gravador registrando um arquivo grande de cada vez em um cartão recém-formatado.
Os tamanhos dos arquivos (30–50 MB) e o nível de preenchimento foram idênticos em ambas as vezes, e limpamos todos os caches antes de cada medição. Os dois layouts não poderiam ser mais diferentes:
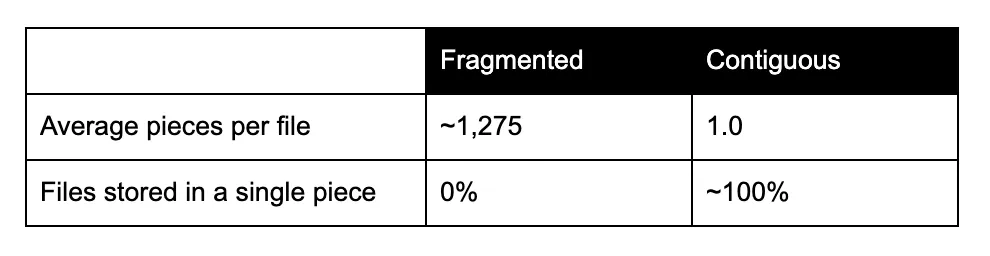
Veja o que isso causou no rendimento:
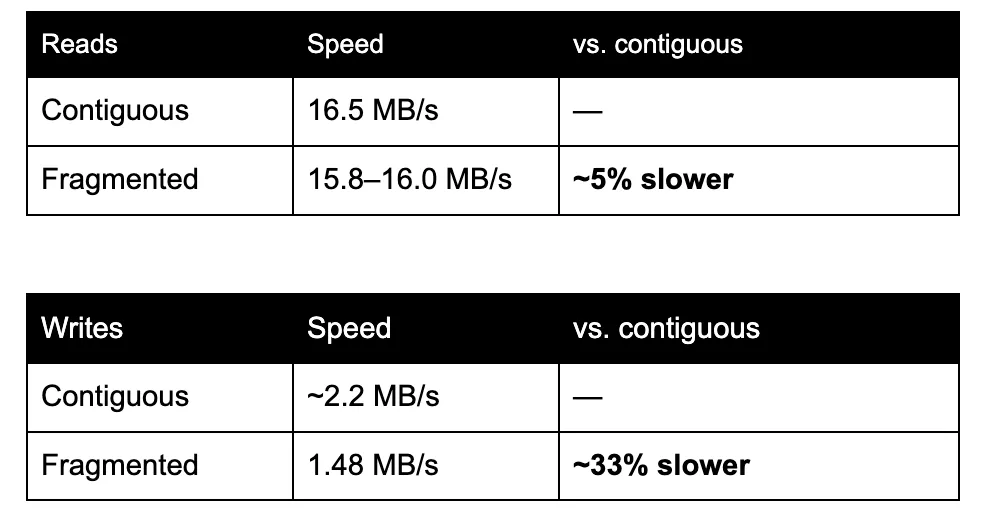
As leituras quase não sofreram impacto, exatamente como a teoria da memória flash prevê. Mas as gravações — a tarefa que uma dashcam realiza a cada segundo de cada viagem — ficaram cerca de um terço mais lentas assim que os dados foram fragmentados, e a diferença se manteve em execuções repetidas.
Uma ressalva: as velocidades absolutas são específicas para este cartão e seu estado atual de NAND, já que cartões SD de consumo não suportam TRIM e o desgaste prévio afeta a taxa de transferência bruta. A grandeza repetível e significativa é a diferença *relativa* — e essa é a parte que a estratégia de gravação controla.
Como é a maioria dos pipelines de dashcam — e o que isso custa
O caminho de menor resistência é deixar que vídeo, áudio, GPS, dados do acelerômetro e metadados de IA gravem e liberem dados conforme seus próprios cronogramas. Isso produz exatamente o padrão de gravação descrito no benchmark acima. Os clusters ficam espalhados pelo cartão. O FTL é forçado a ciclos constantes de leitura-modificação-gravação. As velocidades de gravação ficam um terço abaixo do que o hardware é capaz. E, ao longo de meses de gravação contínua, a amplificação de gravação aumenta — os cartões envelhecem mais rápido do que sua durabilidade nominal, falhando antes do que os operadores de frota planejam.
Não por causa de qualquer defeito no cartão, mas por causa de como o software o trata.
O RideView escolhe o caminho mais difícil.
Como o RideView grava vídeos da maneira correta
O gravador do RideView foi construído para que a fragmentação nunca tenha chance de ocorrer. As escolhas de design refletem diretamente os pontos acima.
O princípio parece simples: o armazenamento flash prefere gravações grandes e sequenciais. A parte difícil é fazer com que uma dashcam real se comporte dessa maneira enquanto grava múltiplos fluxos ao vivo, reage a eventos e protege as filmagens contra travamentos ou perda de energia.
1. Um arquivo multiplexado, não uma pilha de arquivos pequenos.
O RideView multiplexa cada fluxo em um único arquivo de gravação por segmento de tempo, gravado como uma unidade contínua, para que o cartão veja um padrão de gravação mais limpo: menos gravações espalhadas, menor amplificação de gravação, menos desgaste evitável e maior vida útil do cartão.
2. Um único gravador dedicado.
A pior fragmentação em nosso teste veio de gravadores competindo em paralelo. O RideView canaliza toda a gravação através de uma thread de gravação dedicada, para que nada dispute o alocador e o sistema de arquivos possa organizar os clusters em sequências longas e contíguas.
3. Gravações sequenciais grandes e com buffer.
Em vez de realizar várias pequenas gravações dispersas, o RideView armazena os dados em buffer e os grava em blocos grandes, anexando-os sequencialmente em cada arquivo — exatamente o padrão que permite ao FTL preencher blocos de apagamento inteiros de forma limpa.
4. Liberações (flushes) periódicas e baseadas em eventos.
As filmagens não podem ser perdidas em caso de falha, mas liberar os dados após cada quadro dispersaria as gravações e forçaria o FTL a voltar ao seu caminho lento. O RideView realiza a liberação em intervalos ajustados *e* em eventos críticos, como uma possível colisão, equilibrando a durabilidade com um padrão de gravação limpo. Cada gravação é um segmento delimitado e autônomo, garantindo que o comportamento de escrita permaneça previsível durante toda a viagem.
Junte tudo isso e você obtém o padrão sequencial grande, de escritor único e contíguo que venceu o benchmark — não por sorte, mas em todas as câmeras, em todas as viagens.
O maior prêmio: seu cartão realmente dura
Gravações mais rápidas são ótimas. A vantagem a longo prazo é o desgaste.
Cada célula flash só pode ser apagada e reescrita um número limitado de vezes antes de falhar. Para um dispositivo que grava ininterruptamente durante anos, a pergunta que realmente importa não é "quão rápido?", mas "quanto desgaste físico estou criando para cada gigabyte de vídeo que realmente gravo?". Essa proporção é a amplificação de escrita:
amplificação de escrita = bytes fisicamente gravados na memória flash / bytes que o aplicativo solicitou gravar
Um valor de 1,0 é perfeito — nada é desperdiçado. O comportamento de leitura-modificação-escrita do FTL é o que eleva esse número: toda vez que a fragmentação ou gravações dispersas forçam o cartão a reescrever um bloco de apagamento meio vazio, ele grava fisicamente mais do que o aplicativo solicitou. Um fator de 2,0 significa que o cartão está envelhecendo duas vezes mais rápido do que sua durabilidade nominal sugeriria.
Em outras palavras, a amplificação de escrita é apenas a face de longo prazo do mesmo problema que torna as gravações mais lentas. Otimize o padrão de escrita e você resolverá ambos de uma vez.
Como isso se apresenta em nossa frota real
Algumas implementações do RideView utilizam cartões SD que expõem seus próprios contadores internos de integridade, incluindo os totais reais de escrita física versus lógica. Isso significa que não precisamos estimar a amplificação de escrita; podemos lê-la diretamente dos cartões já em uso em campo.
Os dados provêm de uma grande variedade de frotas e veículos implantados em cinco continentes. Em cerca de 4.000 câmeras, incluindo algumas com quase um ano de uso e até 14 TB de vídeo gravado, os números medidos são os seguintes:
Amplificação de escrita (medida em campo)
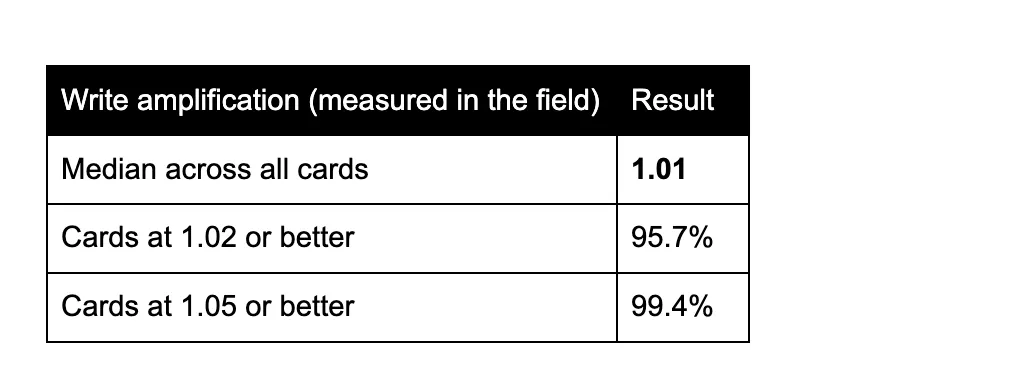
O limite teórico é 1,0, portanto, uma mediana de frota de 1,01 significa que praticamente não há desperdício — e isso em cartões com meses ou anos de gravação, não em hardware novo de fábrica. Na prática, o padrão de escrita é limpo o suficiente para que o cartão SD raramente seja o fator que limita a vida útil de uma câmera.
Por que isso é importante para você
A forma como uma dashcam grava no cartão SD acaba determinando três coisas que realmente importam para você:
- Confiabilidade — gravações que acompanham o ritmo das câmeras significam ausência de quadros perdidos e de falhas nas suas filmagens.
- Margem de segurança — evitar a penalização de fragmentação de ~33% abre espaço para mais câmeras, taxas de bits mais altas e metadados mais ricos no mesmo hardware.
- Custo de propriedade — uma amplificação de escrita próxima de 1,01 significa que os cartões não se desgastam prematuramente, o que resulta em menos falhas e menos substituições.
Nada disso é por acaso. É fruto de entender o que realmente acontece dentro de um cartão de memória flash NAND — indo além da intuição de que "não há peças móveis, então não importa" — e gravar vídeos no único padrão que o hardware realmente aprecia: gravação única, grande, sequencial, contígua e finalizada em um cronograma sensato.
